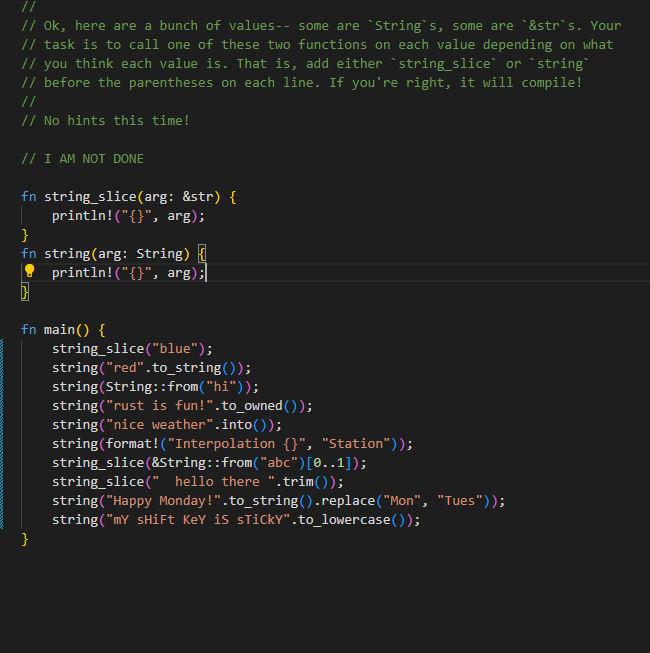
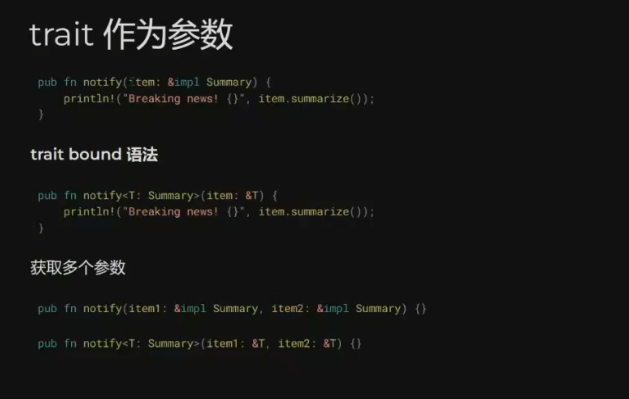
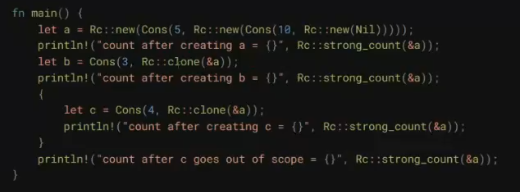
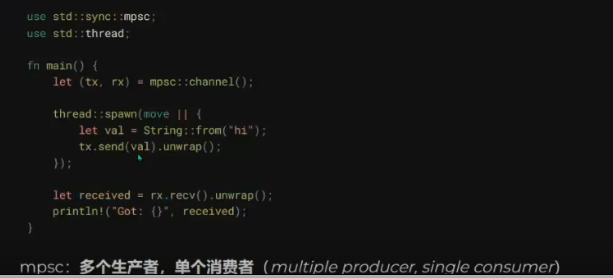
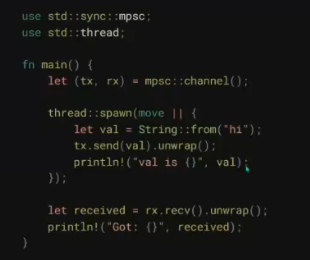
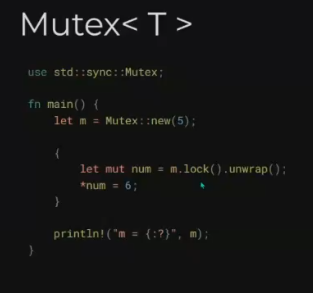
// quiz2.rs // // This is a quiz for the following sections: // - Strings // - Vecs // - Move semantics // - Modules // - Enums // // Let's build a little machine in the form of a function. As input, we're going // to give a list of strings and commands. These commands determine what action // is going to be applied to the string. It can either be: // - Uppercase the string // - Trim the string // - Append "bar" to the string a specified amount of times // The exact form of this will be: // - The input is going to be a Vector of a 2-length tuple, // the first element is the string, the second one is the command. // - The output element is going to be a Vector of strings. // // No hints this time!
fnmain() { let numbers = vec![1, 2, 3, 4, 5]; let sum = numbers.iter().fold(0, |acc, &x| acc + x); println!("The sum is: {}", sum); // 输出:The sum is: 15 }
.fold()迭代器方法
1 2 3
fnfold<B, F>(self, init: B, f: F) -> B where F: FnMut(B, Self::Item) -> B,
这里的参数含义是:
init 是初始值,它是要合并的类型的默认值或起始状态。
f 是一个闭包函数,它接受两个参数:累积值(accumulator)和当前迭代的元素,并返回一个新的累积值。
From 特征允许一种类型定义如何从另一种类型显式地转换,提供了一种类型到另一种类型的单向转换。与 From 特征相对应,Into 特征通常用于相同的转换,实际上当类型实现了 From,Rust 自动为类型提供 Into 实现。两个特征让类型转换变得简单而且类型安全,无需手动处理转换逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13
structNumber { value: i32, } // 为 `Number` 实现 `From<i32>` implFrom<i32> for Number { fnfrom(item: i32) -> Self { Number { value: item } } } let num = Number::from(30); println!("The number is: {}", num.value); let int = 5; let num: Number = int.into();
自动化测试
在使用Rustlings的过程中深刻体会到了Rust内置测试支持的强大之处,无需额外的库就可以编写和运行测试。使用 #[test] 属性标记测试函数,然后使用 cargo test 命令运行所有测试。在 Java 中,即使是未使用的测试代码也可能因为类加载等原因对应用性能有轻微影响,但是Rust 的测试构建只在需要时添加测试代码,不影响生产代码的性能。
letmut arr = vec![1, 2, 3]; letmut i = 0; for elem in &arr { println!("{}",elem); if i == 1 { arr.push(6); } i += 1; }
编译器会拒绝通过,报错如下。
1 2 3 4 5 6 7 8 9 10 11
error[E0502]: cannot borrow `arr` as mutable because it is also borrowed as immutable --> src\main.rs:38:13 | 35 | for elem in &arr { | ---- | | | immutable borrow occurs here | immutable borrow later used here ... 38 | arr.push(6); | ^^^^^^^^^^^ mutable borrow occurs here